Reverse engineering is something of an “acquired skill” and that can be really discouraging for beginners, I know this because I was also a beginner and in a lot of ways I still consider myself one, but alas, it’s something which takes a good amount of time and patience, and also some previous foundational knowledge. That’s not to say that you can’t reverse something without these things, it’s definitely possible. It’s just going to be, most of the time, a lot more difficult.
With that being said, I think it’s worth documenting some of this stuff for others to either learn from or simply look over some of the details behind this work and I’d like to share some of my experiences and whatever else I think could be helpful to any beginner reverse engineers or anyone interested in this sort of thing.
So, this is where Reverse Engineering Adventures comes in.
In this post, I’ll go over some simple foundational stuff that a lot of reverse engineering makes great use of, and we’ll be using an example from some recent work I did which we released recently alongside Sega Dreamcast Info.
Let’s get the “basics” down.
So what really even is reverse engineering? Some areas, such as, static analysis, dynamic analysis, cryptanalysis and decompilation, solely revolve around inspecting the operations themselves as opposed to looking at the data. The data in this case can be something like the plaintext message from an cryptographic function, or the data used by an application at runtime, for example some game assets in a game. These types of RE can be classified separately for this reason, and can be referred to as binary file format RE for example in the last example about game assets, or just “data reverse engineering“.
In a way, it’s as though there are 2 distinct routes of reversing: software reverse engineering or data reverse engineering. This permiates throughout the field. Static analysis is the act of inspecting the software, but simply without any of its data around. Whereas, in contrast, dynamic analysis refers to inspecting the software, but with the execution of the software, the data is then also able to affect the application, thus allowing for further, detailed inspection of the software as it is when it’s running normally.
In the realms of video games, data is represents a large majority of the footprint. In the early years, many novel techniques were employed to get around hardware limitations present on video game consoles at the time and this inspired a lot of different file formats. As games require a lot of assets, models, textures, sound files etc, there’s almost always a need to keep things organised in a way that the game can read the assets as and when it’s necessary to. So, just like zip files are a handy way for you to archive your own personal data, game archive file formats were a big thing in the early years. Some games, who may have been produced by the same developer, may even use the same file format for all of their games.
This first post will go over a simple archive file format I encountered while doing some RE work as part of a release for Vectorman (Unreleased) (for PS2), the post for that will go over some of the more interesting technical aspects of the game but I thought this would be a good example to show how to cover something like an archive file format.
Finding the target
The game is a 3D platformer with a simple frontend, multiple levels, weapons, AI to fight and some objectives to complete. Armed with this knowledge, I knew that there would be at least a collection of 3D models, textures, audio and possibly game logic scripts, so I set out to find where these are stored, so that they can be inspected. The root directory contained only the executable, a file named “SMALLF.DAT”, a disc-configuration file necessary for the platform, and 2 subdirectories which only contained some music files and a few textures.
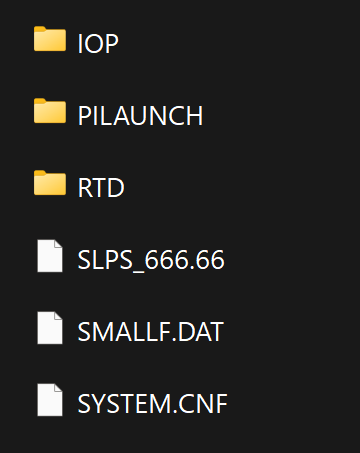
This is a sign that there’s an archive format being used somewhere. While we can see that there are some assets present, it doesn’t seem like everything is there, which is usually a sign that there’s an archive somewhere being used. In this case, the obvious sign here is “SMALLF.DAT”, which, when we open up in a simple hex editor, we can see something interesting:
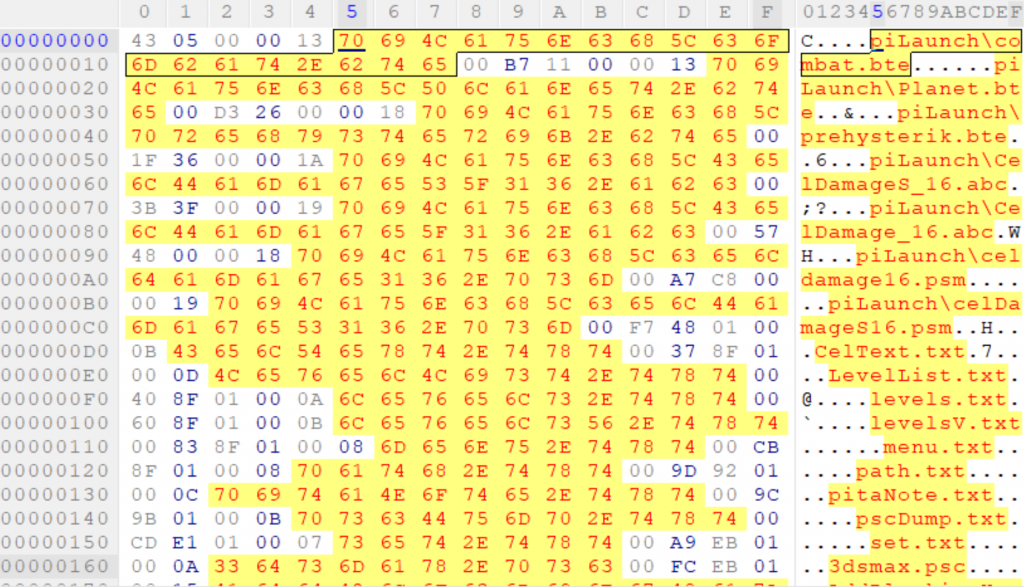
It looks like this is our target, we have a collection of filenames and then the rest of the file just seems to be “random data”, and a quick look over other builds we have access to, it seems like this file is present on every build of the game.
The Method
So first off, we need to check over what exactly we have in that first part of the file. It seems to contain a collection of paths, but there’s also some bytes which aren’t zero and the first 5(?!) bytes seem to be unique.

Starting at those first 5 bytes then, we can see what they represent in decimal… 0x43 is decimal 67.
Hmm, well let’s count how many paths we have…
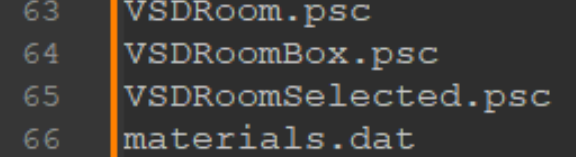
Looks like there are 66 total entries, so maybe this byte represents how many entries there are!
Moving over to offset 0x1, we see bytes 05 00 00. Can’t really make much sense of these at this point, so we’ll just move on to offset 0x4, instead.
Here at 0x4, we have a single byte, with a value of 13. What follows then is the path, and we can see that it ends with a byte of 00, in every instance.. and this pattern becomes evident throughout this entire first half of the file…
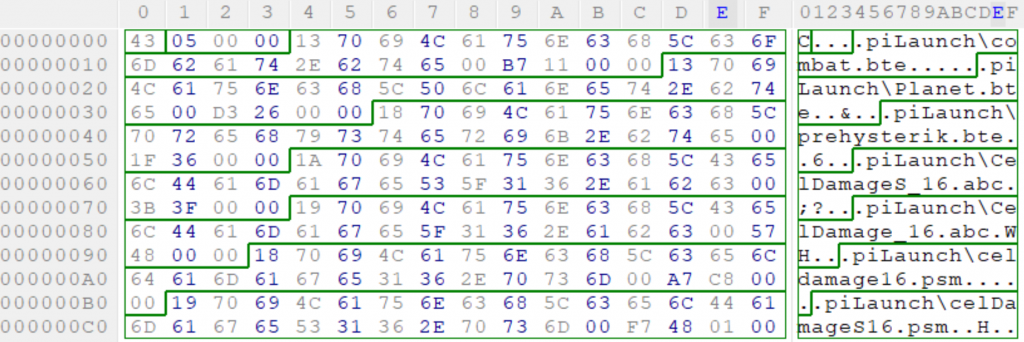
This is an extremely basic overview of how the pattern can start to emerge.
In the C programming language you usually always have some sort of idea as to how much data you might need at a given time, or need in order to perform a certain operation and for strings, that holds true too, as a string in C is just a collection of bytes, followed by a null-byte (00) to denote the end of the string. The pattern which is emerging above seems to suggest that each entry has a single byte before the path, which gives possible values between 0-255. In early versions of Windows and other operating systems, files/paths had a hard-limit of 255 characters, called MAX_PATH.
So.. maybe 13 is representing the number of characters for the path?
13 is decimal 19 and the path associated with it is “piLaunch\combat.bte”.. which is exactly 19 characters long! The pattern seems to be getting a lot clearer now and we map this out a bit better.
It seems as though the first 4 bytes represent an int32_t. This stores data necessary for reading the actual “table of contents” and we refer to it as the header, so we can ignore that for now, let’s concentrate on what is stored for each entry in the table.

What’s left after the path (and the null-byte!) is 4 unique bytes. I call them unique bytes because it seems that each entry in the table has a unique value here each time. But let’s take what we have right now and try to make some sense out of it.
struct Header {
char num_entries;
char unknown_values[3];
};
struct Entry {
char path_size;
string path;
int unknown;
};
struct File {
Header hdr;
std::vector<Entry> entries;
};In essence, this is the pattern that we can see, but represented in C.
This is ultimately the heart of data reverse engineering, we have to take what we know about the data and take any relevant aspects into consideration and try to apply reasoning to the data that we come across.
The remaining pieces of data which are interesting are those 4 bytes which come after each path. Within data reversing, you tend to want to follow the data which correlates to standard C data types firstly before then moving onto the more interesting stuff (for example those “unknown” bytes in Header).
Taking a look at the values then, we can notice a bit of a pattern with them: they only ever seem to increase.
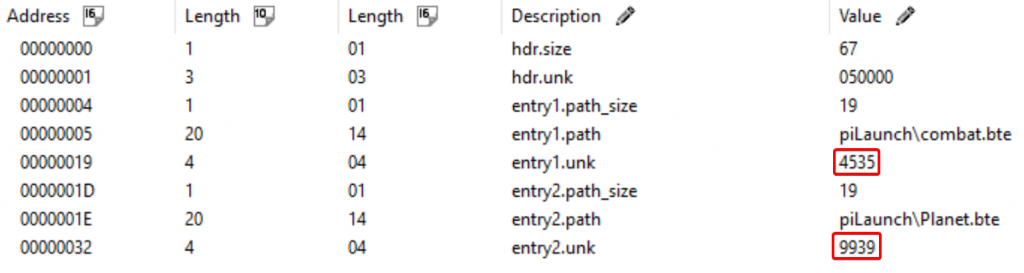
This is interesting, because usually as stated earlier, in the C programming language, you usually always either know or have to know how much data you need to be working with and these values stick out because the very first value, 4535, seems small and the table of contents ends at roughly 0x530 (or decimal 1328).
At this point we could summise that it’s somehow the size of the data itself, or perhaps the offset within the file where this file data is located?
Heading to the location 4535 seems to suggest that it’s not the start location (or “offset”) of the data itself, and it doesn’t seem to be the size of the data, either… but if we were start reading from the end of the header up to location 4535, that seems to make more sense!
It’s hard to tell for sure, since the first entry itself is (another) custom binary file for some sort of game asset, so it’s hard to definitively call it here. However, ironically, we can quite literally perform this investigation in the opposite (or reverse) direction and check the last entry in the file, which is conveniently a regular text file!
In this case the entry is named “materials.dat” and sure enough, the last bytes of the data seem to be some sort of configuration file for the materials used in the game in plain-text! And checking the 4-byte value.. it perfectly aligns!

The 4-byte value for this entry is 197514 and that is exactly after the bytes 0D 0A, which are linefeed and carriage return bytes, denoting the end of the file. All that is left is a bunch of zeroes which seems to pad out the rest of the file up to a certain size, which is a common practice for games of this era which commonly created these file formats with specific specifications in mind so that they could be loaded into memory blocks of varying sizes.
Finishing up
At this point, before continuing, we need to double-check our work and sanity check everything to make sure we are able to fully interpret everything. One thing that is still sticking out is the “header” and those bytes which we don’t really understand yet. However, at this point we have more than enough information to not only extract this data, but also to write these files ourselves (as for the time being we can simply try to reuse any known values and see if those work).
Extraction of the data seemed great.. except there was one fundamental error:
The first byte is not a single byte representing the number of entries, as other samples of “SMALLF.DAT” revealed a different value each time. Upon further inspection, the actual header is just 4 bytes, in this case, 1347.. which is the start location of the file data itself (also, the end location of the header… or the size of the header!).
And with this, we are able to fully interpret and thus extract each entry within the file:
class SmallFile {
public:
struct Entry {
string path;
int offs = 0;
vector<unsigned char> data;
};
SmallFile() = default;
SmallFile(fs::path in) {
read(in);
}
void read(fs::path in)
{
ifstream ifs(in, ios::binary);
int header_size = -1;
ifs.read(reinterpret_cast<char*>(&header_size), 4);
while (ifs.tellg() != header_size-2)
{
char path_len = 0xFFu;
ifs.read(reinterpret_cast<char*>(&path_len), 1);
path_len++;
string path;
while (path_len--)
path.push_back(ifs.get());
int offs = 0xFFFFFFFF;
ifs.read(reinterpret_cast<char*>(&offs), 4);
Entry entry;
entry.path = path;
entry.offs = offs;
Entries.push_back(entry);
}
for (auto& entry : Entries)
{
while (ifs.tellg() < entry.offs)
entry.data.push_back(ifs.get());
}
ifs.close();
}
};This gets us extraction… but what about creation?
In order for us to create the format, we just need to do the complete opposite (again, the reverse operation!) of what we’ve done to extract the files, and instead, we must work backwards and create this data.
So working back on ourselves, we can read every file that we want to put into the archive:
size_t create(fs::path outputDir)
{
for (const auto& p : fs::recursive_directory_iterator(outputDir)) {
if (!fs::is_regular_file(p))
continue;
SmallFile::Entry entry;
entry.path = fs::relative(p.path(), outputDir).string();
printf("Adding '%s'... ", entry.path.c_str());
ifstream ifs(p.path(), ios::binary);
if (ifs.good())
{
ifs.seekg(0, ios::end);
size_t eof = ifs.tellg();
ifs.seekg(0, ios::beg);
while ((size_t)ifs.tellg() < eof)
entry.data.push_back(ifs.get());
printf("(size: 0x%X).\n", (int)entry.data.size());
}
Entries.push_back(entry);
}
return Entries.size();
}So, now, Entries stores all of the data we want to put in already (the second half of the file format), the next step is to now create the “table of contents” (the first half) and for that, we need to precalculate the size of it, so that we can put its size at the beginning of the file (“the header”):
int calc_toc_size()
{
int toc_size = 4; // space for the toc size
for (const auto& entry : Entries)
{
toc_size++; // space for path_len
toc_size += (char)entry.path.size(); // string data
toc_size++; // null-byte
toc_size += 4; // offset
}
return toc_size + 2;
}Here, we simply loop over each entry in the file and account for each byte of data which it takes up.
With this value, we can then simply write out each of the entries, then writing out all of the file data once we’re done!
// write header
int toc_size = calc_toc_size();
ofs.write(reinterpret_cast<char*>(&toc_size), 4);
// write out toc
int last_written_block = toc_size-2;
for (const auto& entry : Entries)
{
last_written_block += (int)entry.data.size();
char path_len = (char)entry.path.size();
ofs.write(reinterpret_cast<char*>(&path_len), 1);
ofs.write(entry.path.c_str(), path_len);
ofs.put(0);
ofs.write(reinterpret_cast<char*>(&last_written_block), 4);
}
// write out all of the entries
for (const auto& entry : Entries)
ofs.write((char*)entry.data.data(), entry.data.size());
// pad it out to 2K boundaries
int aligned_end = (((int)ofs.tellp()) + 2048 - 1) & ~(2048 - 1);
while (ofs.tellp() < aligned_end)
ofs.put(0);
Hopefully this explains some of the mentality and processes that you tend to go through when looking at this sort of thing and is useful to any beginners, or anyone just interested in it.
The full code is available here: